Parallel Programming in Java
Task Parallelism
1.1 Task Creation and Termination (Async, Finish)
1 | S1; |
1.2 Creating Tasks in Java’s Fork/Join Framework
1 | S1; |
1.3 Amdahl’s Law
speedup = 1 / ( 1-p + p/s )
Functional Parallelism
2.1 Futures: Tasks with Return Values
1 | A = future { ⟨ task-with-return-value ⟩ } // assigned a reference to a future object returned by a task of the form |
2.2 Futures in Java’s Fork/Join Framework
- A
Futuretask extends theRecursiveTaskclass in the Fork/Join framework, instead ofRecursiveActionas in regular tasks. - The
compute()method of a future task must have a non-void return type, whereas it has a void return type for regular tasks. - A method call like
left.join()waits for the task referred to by object left in both cases, but also provides the task’s return value in the case of future tasks.
2.3 Memoization
In dynamic programming, the memoization pattern stores { (variables), (future task) } as a lookup table. If the future task exists, look it up and get the return value by get().
2.4 Java Streams
1 | students.stream() |
- The pipeline can be made to execute in parallel by designating the source to be a parallel stream, i.e., by simply replacing
students.stream()in the above code bystudents.parallelStream()orStream.of(students).parallel().
2.5 Data Races and Determinism
- Determinism:
- functional : same input -> same output
- structural : same input -> same competition graph
- Data Races
- Read-write
- Write-write
Loop Parallelism
3.1 Parallel Loops
1 | finish{ |
e.g
1 | for(int i=0;i<n;i++){ |
to
1 | IntStream.range(0, n).paralle().forEach(i -> A[i] = B[i] + C[i]); |
3.2 Parallel Matrix Multiplication
1 | for(i : [0:n-1]) { |
It is safe to convert for-i and for-j into forall loops, but for-k must remain a sequential loop to avoid data race.
3.3 Barriers in Parallel Loops
1 | forall (i : [0:n-1]) { |
3.4 Iteration Grouping/Chunking in Parallel Loops
Use grouping to reduce task number.
Data flow Synchronization and Pipelining
4.1 Split-phase Barriers with Java Phasers
1 | Phaser ph = new Phaser(n); |
Doing so enables the barrier processing to occur in parallel with the call to lookup(i), which was our desired outcome.
4.2 Point-to-Point Sychronization with Phasers
| Task 1 | Task 2 | Task 3 |
|---|---|---|
| X=A() //cost=1 | Y=B() //cost=2 | Z=C() //cost=3 |
| ph0.arrive() | ph1.arrive() | ph2.arrive() |
| ph1.wait() | ph0.wait(), ph2.wait() | ph1.wait() |
| D(X,Y) //cost=3 | E(X,Y,Z) //cost=2 | F(Y,Z) //cost=1 |
Why use Phaser? Because we can split ph.arriveAndAwaitAdvance() into arrive and await
4.3 One-Dimensional Iterative Averaging with Phasers
1 | // Allocate array of phasers |
4.4 Pipeline Parallelism
1 | while ( there is an input to be processed ) { |
4.5 Data Flow Parallelism
A -> C;
A, B -> D;
B -> E
1 | async( () -> {/* Task A */; } ); // Complete task and trigger event A |
The ForkJoinPool
- Use cases: good choice for computation-heavy, divide-and-conquer problems
ForkJoinTaskis abstract: can be implemented byRecurisiveActionorRecurisiveTask- Usages:
execute async execution, with no return value submit async execution, with a return value that can be retrieved by task.get()invoke async execution, and the returned value will be obtained in the caller threads
Concurrent Programming in Java
Threads and Locks
1.1 Threads
| Create a thread | Thread t = new Thread(); |
| Start executing | t.start(); |
| Join and wait | t.join(); |
- Threads provides a low-level function for parallelism
- Since there is no restriction on which thread can perform a join on which other thread, it is possible for a programmer to erroneously create a deadlock cycle with
joinoperations.
1.2 Structured Locks
- Structured lock construct is responsible for both acquiring and releasing the lock that it works with..
- Structured locks can be used to enforce mutual exclusion and avoid data races;
- Structured locks are also referred to as intrinsic locks or monitors.
1
2
3
4
5inc(){
synchronized(A){ // Acquire A
A.count += 1;
} // Release A
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18X {buf, in, out} // A buffer with in and out pointers.
insert(item){
synchronized(X){
wait if the buf is full
buf[in++] = item
in++
notify remove
}
}
remove(){
synchronized(X){
wait if the buf is empty
item = buf[out];
out++;
return item;
notify insert
}
}
1.3 Unstructured Locks
lock and unlock is decided on the programmer’s side. E.g. N1(L1) -> N2(L2) -> N3(L3) -> N4
1 | lock(L1) |
- Unstructured lock supports “hand-over-hand” locking.
- tryLock() will add more flexibility. If the lock cannot be acquired, the algorithm can do some other thing.
Read-write lock:
Multiple threads are permitted to acquire a read lock, but only one thread is permitted to acquire a write lock.
1 | // Let's say there is an array. |
1.4 Liveness
- deadlock: two threads block each other
1
2
3
4
5
6
7
8
9
10
11
12
13
14T1{
sync(A){
sync(B){
...
}
}
}
T2{
sync(B){
sync(A){
...
}
}
} - live lock: continue executon but no progress
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17mutable int x;
T1{
do{
sync(x){
x.incr();
r = x.get();
}
}while(x<2)
}
T2{
do{
sync(x){
x.decr();
r = x.get();
}
}while(x>-2)
} - starvation
Liveness refers to a progress guarantee, i.e, deadlock freedom, livelock freedom, and starvation freedom.
1.5 Dining Philosophers
Some philosophers sit at a round table, and they will repeatly think, pick up chopsticks, eat, put down chopsticks.
with structured lock
1
2
3
4
5
6
7
8while(true){
think
sync(left){
sync(right){
eat
}
}
}This implementaion will cause deadlock
with structured lock
1
2
3
4
5
6
7
8while(true){
think
s1 = tryLock(left)
if(!s1) continue
s2 = tryLock(left)
if(!s2) continue
eat
}There is no deadlock because we are using tryLock. But livelock is possible.
Solution:
- Modify and let at least one philosopher, E, pick up right first then left
- The philosophers that sit on odd seats pick up left first, while the ones that sit on even seats pick up right first.
- Only pick up both chopsticks when both are available
Critical Sections and Isolation
2.1 Critical Sections
Use isolate to denote critical sections
1 | //I transfer money via the family account to daughter |
2.2 Object Based Isolation (Monitors)
A linked list
1 | delete(cur){ |
The relationship between object-based isolation and monitors is that all methods in a monitor object, M1, are executed as object-based isolated constructs with a singleton object set, {M1}. Similarly, all methods in a monitor object, M2, are executed as object-based isolated constructs with a singleton object set, {M2} which has an empty intersection with {M1}.
2.3 Concurrent Spanning Tree Algorithm
1 | compute(v){ //parallelize the spanning tree computation |
2.4 Atomic Variables
A shared value like cur performs cur = cur + 1. It can be replaced by an atomic integer:
1 | AtomicInteger cur = new AtomicInteger(); |
Atomic reference uses compareAndSet
1 | AtomicReference ref = new AtomicReference(); |
1 | compareAndSet(expected, new){ |
2.5 Read, Write Isolation
The main idea behind read-write isolation is to separate read accesses to shared objects from write accesses.
Actors
3.1 Actors
An Actor uses object-based isolation. It forces all accesses to an object to be isolated by default.
| Actor |
|---|
| Mailbox |
| Methods |
| Local State |
The Actor model is reactive. It means actors can only execute methods in response to messages; these methods can read/write local state and/or send messages to other actors.
Thus, the only way to modify an object in a pure actor model is to send messages to the actor that owns that object as part of its local state. In general, messages sent to actors from different actors can be arbitrarily reordered in the system. However, in many actor models, messages sent between the same pair of actors preserve the order in which they are sent
3.2 Actor Examples
A pipeline checks if the word consists of all lower-case characters, and then checks if the word is even length.
1 | process(s){ // y: checks if the word consists of all lower-case characters |
3.3 Sieve of Eratosthenes Algorithm
To implement the Sieve of Eratosthenes, we implement a actor pipeline:
Non-Mul-2 -> Non-Mul-3 -> Non-Mul-5 -> Non-Mul-7 -> …
A Java code sketch for the process() method for an actor responsible for filtering out multiples of the actor’s “local prime” in the Sieve of Eratosthenes is as follows:
1 | public void process(final Object msg) { |
3.4 Producer-Consumer Problem
1 | comsumer-thread(){ |
If solve this problem by using locks with wait-notify operations or by using object-based isolation, both approaches will require low-level concurrent programming techniques to ensure correctness and maximum performance.
However, we can do it using Actor
1 | comsumer-actor(){ |
3.5 Bounded Buffer Producer-Consumer Problem

Concurrent Data Structures
4.1 Optimistic Concurrency
1 | Atomic Integer{ |
- no deadlock because there is no blocking
- no livelock because one eventually makes progress
4.2 Concurrent Queue
1 | Queue{ |
Make queue to be more friendly in multi-threaded situations.
1 | Queue{ |
4.3 Linearizability
- When the value is written, all reads will return the modified value
- Read will return the value that is got between request and response.
4.4 Concurrent Hash Map
1 | ConcurrentHashMap{ |
Distributed Programming in Java
Distributed Map Reduce
1.1 Introduction to Map-Reduce
- Map:
(KA,VA) -> (KA1, VA1), (KA2, VA2);(KB,VB) -> (KB1, VB1), (KB2, VB2) - Group the same intermediate key: if
KA1=KB1=K, then we have(K, (VA1,VB1)) - Reduce:
Gis a user-specified funciton,(K, G(VA1,VB1))
1.2 Hadoop Framework
Apache Hadoop implements distributed Map-Reduce.
A distributed computer can be viewed as a large set of multicore computers connected by a network, such that each computer has multiple processor cores. Each computer has some storage.
Hadoop allows the programmer to specify map and reduce functions in Java, and takes care of all the details of generating a large number of map tasks and reduce tasks to perform the computation as well as scheduling them across a distributed computer.
Hadoop is fault tolerant in that if a node fails, the task can be re-executed with the same input elsewhere.
Hive and Pig (query language) can perform word-count.
The input K-V pairs distribute among computers,
map them to intermediate key-value pairs,
group by intermediate key,
and sreduce.
1.3 Spark Framework
| Hadoop | Spark |
|---|---|
| The computers in the distributed computer use memory just to stream data from disks, perform map or reduce operations, stream the data back to the disk | The computers in the distributed computer use memory as data buffer and perform computation on them |
| K-V pairs | resilient distributed datasets |
| Map-reduce | More operations: transforms (intermediate operations), like map, filter, join…; actions (terminal operations), like reduce, collect… |
Spark has two innovations:
- lazy evaluation: don’t need to schedule intermediate operations until you know what the terminal operations
- caching in memory: read and write data from memory -> faster
Word-count example:
- sc = new JavaSpackContext();
- input = sc.textFile(inputPath);
- words = input.flatMap(line -> line.split(“ “));
- pairs = words.mapToPair(word -> new Tuple2<String, Integer>(word, 1));
- counts = pairs.reduceByKey((a,b)->a+b);
1.4 TF-IDF Example
Term Frequency – Inverse Document Frequency: to identify documents that are most similar to each other within a large corpus.
| | D1 | D2 | … | DN | DF |
| - | - | - | - | - | - |
| Term1 | TF1,1 | TF1,2 | | TF1,N | DF1 |
| Term2 | TF2,1 | TF2,2 | | TF2,N | DF2 |
- TFi,j - term frequency: Termi frequency in Dj
- DFi - document frequency: the count of Termi in documents
- IDF - inverse document frequency: N/DF
- weight of Termi in Dj = TFi,j * log( N/DFi )
Calculate using Hadoop:
- input: (document, {terms})
- map: (document, {terms}) -> ((document, term), 1)
- reduce: ((document, term), TF)
- map: ((document, term), TF) -> (term, 1)
- reduce: (term, DF)
1.5 Page Rank Example
![]()
1 | for (iter=...) { |
Calculate using Spark:
1 | contribs = links.join(ranks).values() |
Client-server Programming
2.1 Introduction to Sockets
Client-server programming is typically used for building distributed applications with small numbers of processes.
1 | // Get communications on JVM A and JVM B:s |
Sockets logically connect two JVMs, but what actually happens physically is that the message has to go through the network from the client to the server and the server to the client.
2.2 Serialization/Deserialization
Serialization: objects to bytes
Solutions:
- Custom serialization/deserialization
- XML
- Java serialization/deserialization Transient: annotate fields should not be copied
1
class X implements Serializable
- IDL(interface definition language)
- instance: protocal buffer
- pros: communicate not just in Java, but in other languages like Python
- cons: programmers have to define the interface in
.proto
2.3 Remote Method Invocation
Thread on JVM A wants to call method of object x on JVM B, and get a return value y.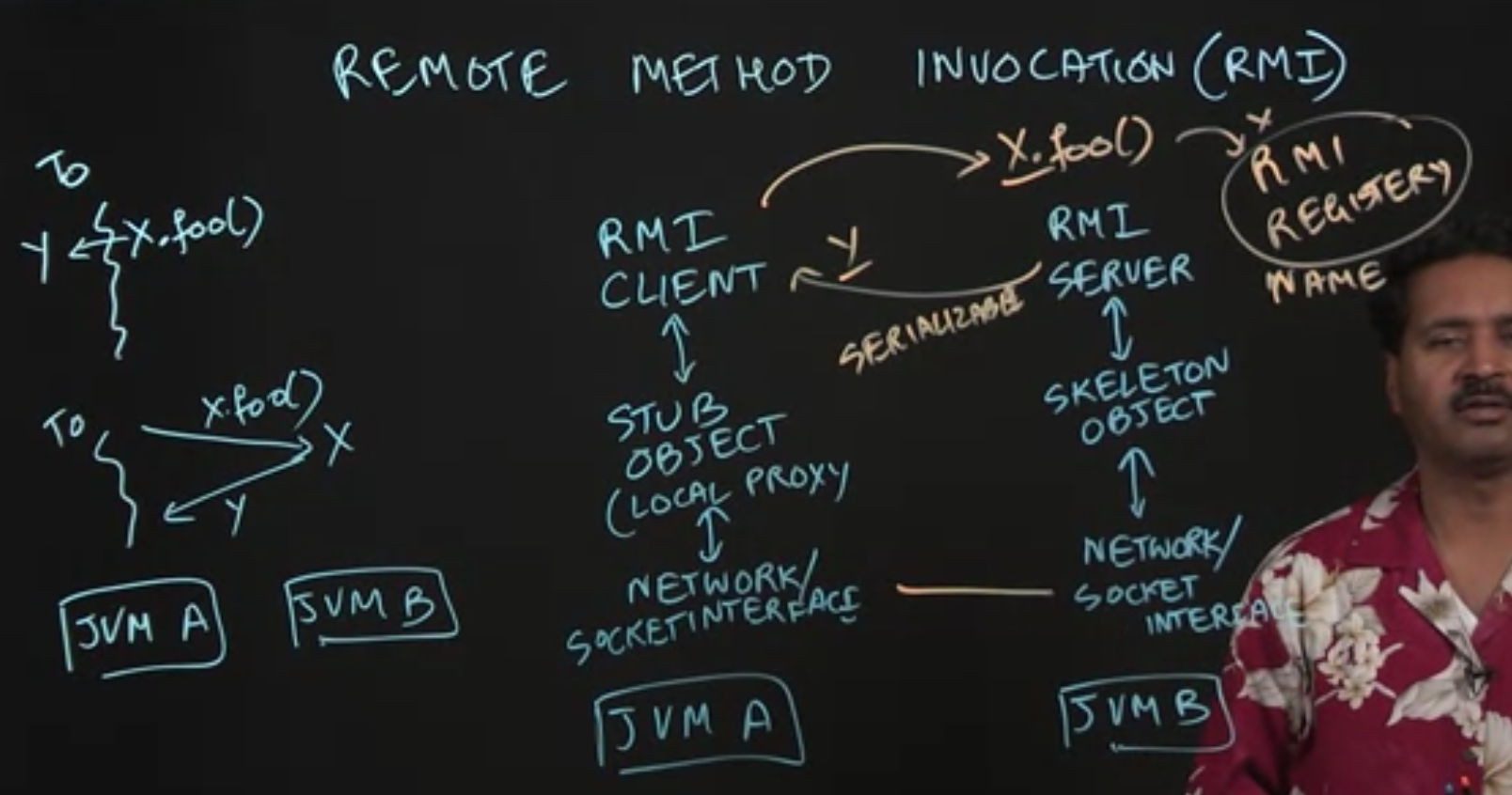
Both x and y should be serialiable. Object x must be included in the RMI registry, so that it can be accessed through a global name rather than a local object reference.
In summary, a key advantage of RMI is that, once this setup in place, method invocations across distributed processes can be implemented almost as simply as standard method invocations.
2.4 Multicast Sockets
| Unicast | Broadcast | Multicast |
|---|---|---|
| src sends message to dest through routers | src sends message to a router, and to all dests that are connected to the router in the local network | src sends message to multiple dests through cloud |
| single destination, point-to-point communication | multiple destination, in local network | multiple destination, through cloud/Internet |
In Java
1 | s = new MulticastSocket(port); |
2.5 Publish-Subscribe Model
We have some producers and consumers. Producers send messages to topics, while consumers read messages from topics. Topics work as a broker, which producers publish messages to and consumers poll messages from.
1 | //producer |
Message Passing
3.1 Single Program Multiple Data (SPMD) model
Different nodes work on different local elements of a global variable. The interface available is MPI (Message passing interface)
1 | // global view: XG, local view: XL |
3.2 Point-to-Point Communication
1 | // In rank0, s="ABCD" and send s to rank1 |
1 | main(){ |
If sending objects, the object has to implement Serializable
3.3 Message Ordering and Deadlock
| R0 | R1 | R2 | R3 |
|---|---|---|---|
| R0 wants to receive message from R1 | |||
| R1 wants to send message to R0 | R2 wants to send message to R3 | ||
| R3 wants to receive message from R2 |
The same order is only guaranteed if the sender, the receiver, the data type and the tag is the same for two messages. In this case, the order of R0 receiving or R3 receiving message is not guaranteed.
| R0 | R1 |
|---|---|
| send x to R1 | send y to R0 |
| receive y from R1 | receive x from R0 |
Send and receive in MPI are blocking operations. In this case, send x to R1 will wait until a receive is detected.
Solution 1:
R0 R1 send x to R1 receive x from R0 receive y from R1 send y to R0 Solution 2: the API will avoid deadlock by single send or receive
R0 R1 sendrecv(x) sendrecv(y)
3.4 Non-Blocking Communications
Benefits: avoid idle time between blocking send and recv
| R0 | R1 |
|---|---|
| S1: req0 = isend | S2: req1 = irecv |
| S3 | S4 |
| wait(req0) | wait(req1) |
| S5 | S6 |
Other operations: waitAll and waitAny
3.5 Collective Communication
1 | main(){ |
Combining Distribution And Multi-threading
4.1 Processes and Threads
| Multiple threads in a process | Multiple processes in a node |
|---|---|
| memory or resource efficiency, due to sharing | responsiveness to, for example, JVM delays |
| responsiveness to network delays | scalability (improve throughput) |
| performance | availability (also referred to as resilience) |
4.2 Multithreaded Servers
1 | listener = new ServerSocket(…); |
There is an overhead when creating a new thread each time. It can be solved by using thread pool.
4.3 MPI and Threading
1 | // master thread |
- threading modes:
funneled all MPI calls are performed by one thread serialized at most have one MPI call at a time multiple multiple called at the same time
4.4 Distributed Actors
If we have large numbers of actors, it will be too much to run them all on a single node.
Solution: put future actors on a new different node.
- Create a configuration file. That tells you for each actor, what the host and port is for that actor to receive messages remotely
- Create remote actors
- Look up remote actors by some kind of logical name
- Messages need to be serialized.
4.5 Distributed Reactive Programming
It’s best to implement distributed service oriented architectures using asynchronous events. A key idea behind this model is to balance the “push“ and “pull“ very efficiently.
Reactive streams specification:
1 | Flow.Publisher |
1 | // publisher |
1 | // subscriber |

